











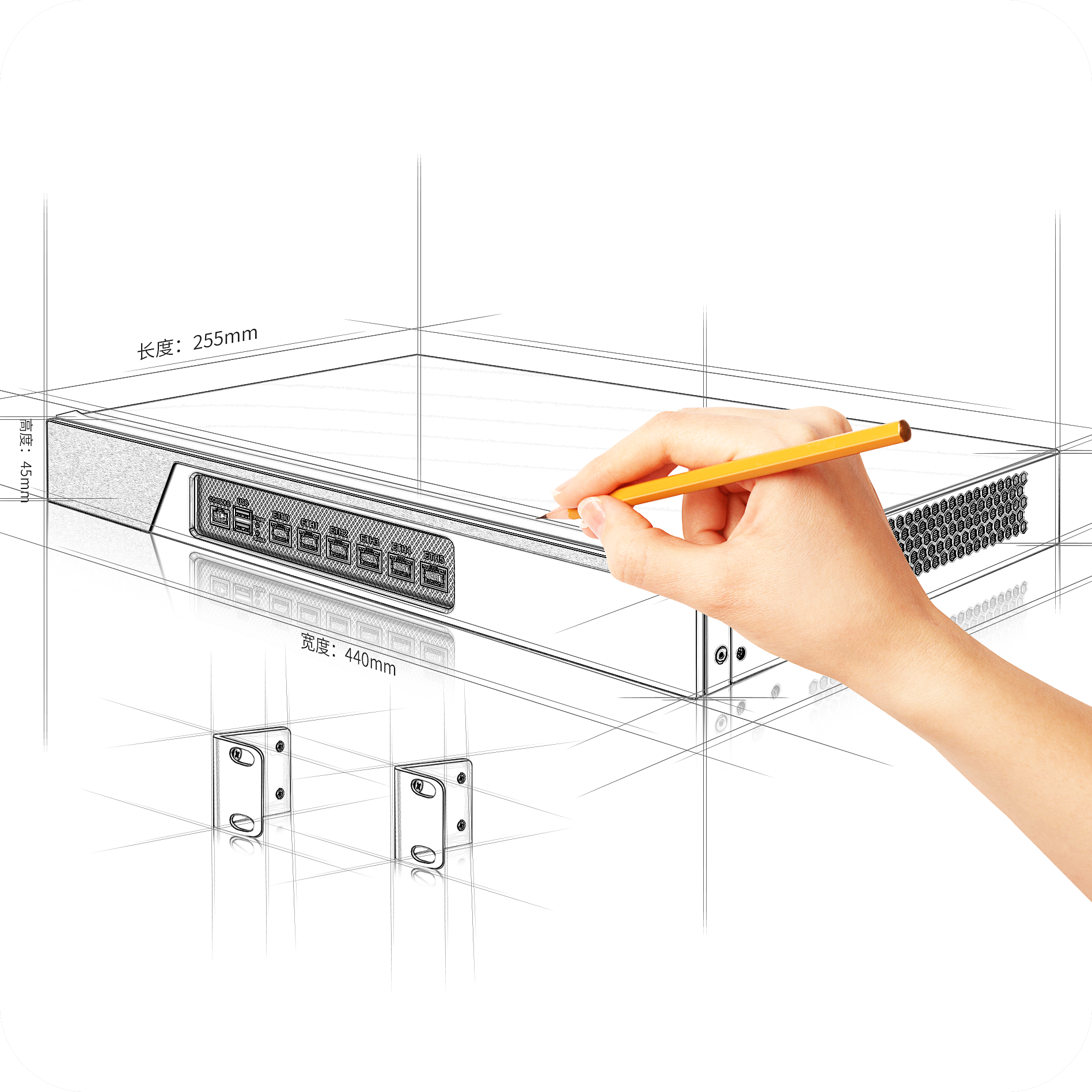


















AI算力硬件服务器解决方案
高性能GPU加速计算平台,为人工智能、深度学习和科学计算提供强大的算力支持
下一代AI计算基础设施
我们的AI算力服务器解决方案基于最新的GPU加速技术,提供前所未有的计算性能。专为深度学习训练、推理和大规模并行计算设计,能够显著缩短模型训练时间,加速AI应用落地。
系统采用模块化设计,支持多GPU扩展和高速互连技术,提供高达10PFLOPS的计算能力。优化的散热架构和能效管理,确保7x24小时稳定运行,满足企业级AI工作负载需求。
10 PFLOPS
峰值计算性能
8x GPU
扩展能力
200 TB
高速存储
70%
能效提升
应用场景
为各种AI工作负载提供强大的计算支持
深度学习训练
为大规模神经网络训练提供强大的计算能力,显著缩短训练时间
- 支持多GPU并行训练
- 高速NVLink互连技术
- 大规模数据集处理
- 分布式训练支持
AI推理服务
高吞吐量、低延迟的推理服务,满足实时AI应用需求
- 毫秒级推理延迟
- 高并发处理能力
- 模型优化与压缩
- 动态批处理支持
科学计算
加速复杂科学计算任务,包括分子模拟、气候建模等
- 分子动力学模拟
- 气候预测模型
- 计算化学
- 大数据分析
计算机视觉
实时视频分析、图像识别和处理应用
- 实时目标检测
- 高分辨率图像处理
- 3D重建与渲染
- 地理空间分析
技术优势
领先的AI算力服务器技术特点
极致计算性能
搭载最新NVIDIA A100/H100 GPU,提供高达10PFLOPS的混合精度计算能力
高速互连技术
采用NVLink 4.0技术,提供900GB/s的GPU间带宽,是PCIe 5.0的7倍
高效散热系统
液冷与风冷混合散热方案,支持3500W GPU TDP,确保长时间高负载稳定运行
灵活扩展架构
模块化设计,支持8路GPU扩展,可按需配置计算密度
高能效设计
智能功耗管理,每瓦特性能提升40%,显著降低TCO
云原生支持
集成Kubernetes和容器技术,支持混合云部署和弹性伸缩
产品规格
多款型号满足不同规模AI计算需求
AI-3000系列
AI-5000系列
AI-7000系列
处理器
- CPU2x AMD EPYC 9654
- 核心/线程192/384
- 基础频率2.4GHz
内存
- 容量2TB
- 类型DDR5 4800MHz
- 通道16通道
GPU配置
- 数量4x NVIDIA H100
- 显存80GB HBM3
- 互连NVLink 4.0
存储
- 系统盘2x 3.84TB NVMe
- 数据盘8x 15.36TB SSD
- 扩展支持JBOD扩展
网络
- 网卡2x 100GbE
- 协议RoCEv2, iWARP
- 管理1x 1GbE
性能
- FP6440 TFLOPS
- FP16320 TFLOPS
- TF32160 TFLOPS